- Published on
DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
- Authors

- Name
- AIFlection
DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
Introduction: Scaling AI Training Efficiently
Training large-scale AI models is not just about smarter algorithms but also about maximizing the efficiency of hardware infrastructure. DeepSeek-V3, despite having 671 billion parameters, was trained on only 2,048 NVIDIA H800 GPUs, achieving GPT-4 level performance at a fraction of the usual cost.
This feat was not accidental — it was a result of careful hardware optimizations at every level, from GPU interconnect strategies to parallelism techniques. In this blog, we will explore how DeepSeek-V3 engineers minimized bottlenecks, optimized GPU-to-GPU communication, and ensured maximum hardware utilization to push the boundaries of efficient AI training.
Understanding the GPU Cluster: 2048 H800s and High-Bandwidth Interconnects
DeepSeek-V3 was trained on a 2,048 GPU cluster, each NVIDIA H800 GPU containing 80GB of HBM3 memory. The cluster was arranged in compute nodes, where each node contained 8 GPUs connected via NVLink/NVSwitch, while nodes were interconnected using InfiniBand (IB) networks.
This hybrid interconnect strategy was crucial for minimizing latency when exchanging gradients, activations, and expert-routing information.
Let’s break down how the communication works in multi-GPU training.
Optimized GPU Interconnect: NVLink vs. InfiniBand
Each compute node contained 8 GPUs communicating through NVLink/NVSwitch, which allows for intra-node bandwidth of up to 900 GB/s. However, NVLink does not scale beyond a single node, so for cross-node communication, DeepSeek-V3 leveraged InfiniBand, which provides 200–400 Gbps per link but is significantly slower than NVLink.
The Problem: Costly Cross-Node Communication
A naïve MoE (Mixture of Experts) setup would result in highly inefficient communication, where tokens route to experts across thousands of GPUs. If every token needed to fetch parameters from any GPU in the cluster, the cross-node traffic would explode, leading to severe latency and poor utilization of hardware resources.
To prevent this, DeepSeek-V3 limited expert routing to at most 4 nodes per token, ensuring that the bulk of communication remained within NVLink rather than InfiniBand, significantly reducing inter-node bandwidth overhead.
Mathematically, if a token would normally route to N GPUs, the communication cost scales as:

By limiting this routing to a constant k=4k = 4, the cross-node overhead remains bounded, improving training efficiency.
DualPipe Parallelism: Eliminating Pipeline Idle Time
The Problem: Traditional Pipeline Parallelism Leaves GPUs Waiting
When training large models, it is common to split the network into multiple pipeline stages, distributing different parts of the model across different GPUs. A standard 1F1B (one forward, one backward) pipeline introduces idle bubbles, meaning some GPUs are left waiting while others complete their computation.
For example, if a 4-stage pipeline has microbatches flowing one at a time, some GPUs are inactive while waiting for their turn.
The Solution: DualPipe Parallelism
DeepSeek-V3 used DualPipe, a custom pipeline parallel scheduling algorithm that overlaps computation and communication in a way that keeps all GPUs active almost all the time.
DualPipe requires that:
- The number of microbatches is divisible by 2, ensuring a balanced pipeline.
- Stages alternate between forward and backward passes, meaning while one GPU is computing a forward pass, another is already processing a backward pass.
Instead of idle bubbles, DualPipe fills these gaps with useful work, leading to near-theoretical throughput.
Mathematically, if traditional pipeline parallelism has an idle fraction II per GPU, DualPipe minimizes it to almost zero:
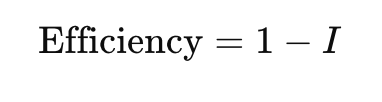
Since DeepSeek-V3 carefully tuned the communication chunk sizes using low-level CUDA/PTX optimizations, the pipeline overhead was reduced, allowing seamless overlap of computation and communication.
Parallelism Strategy: Data Parallel + Expert Parallelism
Instead of relying on tensor parallelism, which requires frequent GPU synchronization, DeepSeek-V3 used a simpler and more scalable strategy:
- Data Parallelism (DP): Each batch of data was split across multiple GPUs.
- Expert Parallelism: MoE experts were distributed across GPUs, meaning tokens only communicated with the GPUs storing the experts they needed.
This avoided costly all-reduce operations, which are required in tensor parallel training. Instead of sharding a layer’s parameters across multiple GPUs, DeepSeek-V3 stored each expert’s parameters fully on a single GPU, reducing inter-GPU communication.
Mathematically, if a fully tensor-parallel model requires all-reduce synchronization per layer O(N), DeepSeek-V3’s expert parallelism only needs local communication per token:
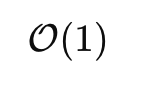
This is why DeepSeek-V3 scaled efficiently across thousands of GPUs.
Customized GPU Kernels and Precision Optimization
DeepSeek-V3 also optimized low-level GPU operations to maximize hardware throughput.
Using FP8 for Communication Efficiency
MoE models require frequent token routing, meaning activations need to be transferred across GPUs. Instead of sending these activations in full precision (FP16/BF16), DeepSeek-V3 quantized activations to FP8 before transmitting, cutting bandwidth usage by 4x.
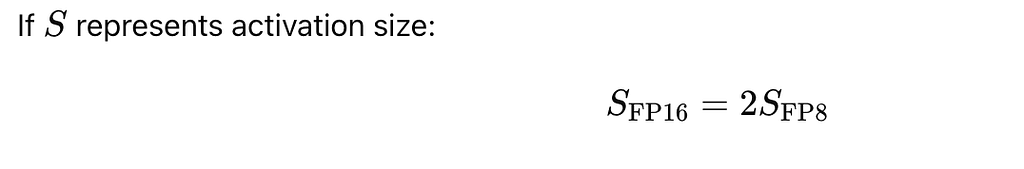
Thus, sending activations in FP8 allowed four times more data to fit into the same memory bandwidth.
Warp-Group Matrix Multiply (WGMMA) for FP8 Acceleration
DeepSeek-V3 leveraged NVIDIA’s WGMMA instructions to ensure that FP8 multiplications were executed without stalling. These instructions convert FP8 values to higher precision before multiplication, ensuring accuracy is preserved while keeping throughput high.

This ensured that FP8 operations ran at peak speed without accumulating excessive numerical errors.
Challenges and Trade-offs
Reducing Cross-Node Communication Can Introduce Bottlenecks
Limiting MoE routing to 4 nodes per token improves efficiency, but it constrains flexibility. If a certain expert is more useful for a given token but resides outside the 4-node boundary, performance may suffer slightly.
DualPipe Requires Careful Microbatch Tuning
While DualPipe eliminates pipeline stalls, it requires careful balancing of microbatch size and pipeline depth. If microbatch count is not tuned properly, some GPUs may still experience minor idle times.
Inference Scalability
Even though training was optimized efficiently, inference still requires selecting the right expert routing dynamically. DeepSeek-V3 compensates by caching shared experts to reduce overhead, but real-world inference will require further optimizations for seamless scalability.
Conclusion: A Masterclass in Hardware Optimization
DeepSeek-V3’s hardware-level optimizations enabled it to train a 671B-parameter model on just 2,048 GPUs, dramatically reducing costs.
By combining:
- Optimized MoE routing to minimize cross-node communication
- DualPipe parallelism to eliminate pipeline idle time
- Expert parallelism instead of tensor parallelism to reduce synchronization overhead
- FP8 activation quantization for faster token routing
DeepSeek-V3 demonstrates what is possible when AI models are designed for hardware efficiency from the ground up.
In the next blog, we will explore inference-time optimizations, including multi-token prediction and speculative decoding, which allow DeepSeek-V3 to generate responses faster than traditional transformers.
All Blog Links:
1. Blog-1: DeepSeek-V3 Blog 1: Redefining AI Efficiency — An Exclusive Series
2. Blog-2: DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
3. Blog-3: DeepSeek-V3 Blog 3: Smarter Memory Optimization — The Key to Training a 671B Model on Just 2048 GPUs
5. Blog-5: DeepSeek-V3 Blog 5: Low-Precision Training — The FP8 Revolution in Large-Scale AI
6. Blog-6: DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
7. Blog-7: DeepSeek-V3 Blog 7: Faster Inference with Shared Experts — The Key to Efficient AI Generation
8. Blog-8: DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together