- Published on
DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together
- Authors

- Name
- AIFlection
DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together
DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together
Introduction: The Art of Efficiency in AI
Over the course of this blog series, we have taken a deep dive into DeepSeek-V3, a model that redefines efficiency in large-scale AI. From Mixture of Experts (MoE) to low-precision FP8 quantization, from hardware-level optimizations to Multi-Token Prediction (MTP), we have examined every key ingredient that makes this model a marvel of AI engineering.
This final blog is about connecting the dots — how all these independent innovations work together to form a highly efficient, cost-effective, and scalable AI model. We will explore how DeepSeek-V3 achieves its GPT-4 level capabilities at just a fraction of the cost, and what this means for the future of AI.
The Central Problem: Scaling AI Without Exponential Costs
Scaling large language models has always been a delicate balance.
- Bigger models = better performance (up to a certain limit).
- More parameters = more memory and compute required.
- More computation = higher costs and slower inference.
Most organizations solve this by throwing more hardware at the problem — massive clusters of GPUs, extreme memory pooling, and heavy communication networks. This was the approach taken by OpenAI with GPT-4 and Google with Gemini.
DeepSeek-V3, however, took a different approach — instead of brute force, they focused on smart optimizations at every level of the AI stack.
Breaking Down DeepSeek-V3’s Efficiency Formula
Let’s examine the key techniques that allowed DeepSeek-V3 to train a 671B parameter model for only $5M — a 10x cost reduction compared to similar models.
1. MoE-Based Sparsity: Activating Only What’s Needed
Instead of using all 671B parameters at once, DeepSeek-V3 activates only 37B parameters per token.

2. Hardware-Aware Parallelism: Maximizing GPU Utilization
Training a model of this scale could have led to massive inefficiencies if GPU resources were wasted. DeepSeek-V3 avoids this through:
- DualPipe Parallelism — Overlapping forward and backward passes to remove GPU idle time.
- Expert Parallelism — Assigning MoE experts across GPUs to avoid tensor parallelism overhead.
- NVLink Optimization — Keeping most communications within a single node to minimize bandwidth bottlenecks.
By keeping data movement constrained, DeepSeek-V3 maximized throughput and minimized expensive cross-node traffic.
3. Memory-Efficient Training: Squeezing More into Each GPU
Most large-scale models shard weights across multiple GPUs (tensor parallelism), introducing expensive all-reduce operations.
DeepSeek-V3 avoided tensor parallelism entirely by:
- Using MoE to distribute experts instead of splitting dense layers.
- Applying memory optimization techniques like gradient checkpointing.
- Keeping optimizer states in CPU RAM to free up GPU memory.
Memory Usage Optimization Example
A naive model of this size might require over 50GB per GPU for activations alone.
By recomputing activations on the backward pass, this requirement dropped significantly:

where cc is the compression factor from recomputation (typically between 2–4x savings).
This allowed DeepSeek-V3 to run efficiently on 80GB H800 GPUs without needing additional offloading mechanisms.
4. Low-Precision Training: FP8 Quantization for Faster Compute
Lowering precision without losing numerical stability was a key breakthrough.
- FP8 for forward activations and gradients — Cutting memory in half compared to FP16.
- Block-wise quantization — Assigning different scaling factors per weight group to maintain accuracy.
- Higher-precision accumulation — Storing intermediate results in BF16 to prevent drift.
Mathematical Representation
A standard FP16 model would require double the memory for matrix multiplications:
But with FP8, DeepSeek-V3 halved its memory footprint while still maintaining performance.
5. Multi-Token Prediction: Faster Inference Without Extra Compute
DeepSeek-V3 doesn’t just predict the next token — it also learns to predict multiple tokens ahead.
- During training, it optimizes for both the next token and the token two steps ahead.
- During inference, this allows speculative decoding, effectively generating tokens in parallel.
This means DeepSeek-V3 can decode up to twice as fast without additional compute overhead.
How Does This Work Mathematically?
If standard autoregressive inference requires TT forward passes for TT tokens, the speculative decoding method allows:
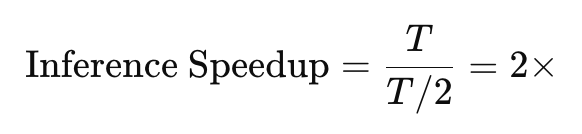
This means a model that previously generated 10 tokens per second can now generate 20 tokens per second, doubling efficiency.
The Future of AI Models: What Comes Next?
DeepSeek-V3 represents a new paradigm in AI model training and deployment.
- It proves that massive models can be efficient if designed carefully.
- It challenges the notion that only the richest companies can train GPT-4 scale models.
- It sets a blueprint for future research on efficient AI architectures.
We are entering an era where efficiency matters as much as scale, and DeepSeek-V3 is leading that shift.
Final Thoughts: The DeepSeek-V3 Blog Series in Retrospect
Throughout this blog series, we have explored every crucial innovation that makes DeepSeek-V3 a breakthrough AI model.
From MoE sparsity to hardware-level optimizations, from low-precision FP8 training to speculative decoding, we have seen how careful engineering decisions can transform AI scalability.
DeepSeek-V3 is more than just a model — it’s a statement that smart design can rival brute force computation.
If you’ve followed along through these blogs, you now understand one of the most sophisticated AI architectures ever built. And as AI research continues to evolve, these principles will define the next generation of models.
What’s Next?
This concludes our DeepSeek-V3 series, but the world of AI is evolving fast. New models, new architectures, and new breakthroughs are on the horizon.
Stay tuned as we continue to explore the frontier of AI research, breaking down the most advanced papers so you don’t have to.
All Blog Links:
1. Blog-1: DeepSeek-V3 Blog 1: Redefining AI Efficiency — An Exclusive Series
2. Blog-2: DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
3. Blog-3: DeepSeek-V3 Blog 3: Smarter Memory Optimization — The Key to Training a 671B Model on Just 2048 GPUs
5. Blog-5: DeepSeek-V3 Blog 5: Low-Precision Training — The FP8 Revolution in Large-Scale AI
6. Blog-6: DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
7. Blog-7: DeepSeek-V3 Blog 7: Faster Inference with Shared Experts — The Key to Efficient AI Generation
8. Blog-8: DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together