- Published on
DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
- Authors

- Name
- AIFlection
DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
Introduction: Why Mixture of Experts (MoE) Matters More Than Ever
Modern AI models are growing at an unprecedented pace. With models surpassing trillions of parameters, training and inference costs are skyrocketing. While traditional dense transformer architectures activate all parameters for every input, Mixture of Experts (MoE) introduces a smarter way: activating only the most relevant parameters for each token.
DeepSeek-V3 takes MoE optimization to the next level by refining expert routing, reducing communication overhead, and introducing shared expert layers that drastically improve efficiency. This blog dives into how DeepSeek-V3 has redefined MoE with its custom expert selection, sparse activation strategy, and memory-efficient parallelism — achieving GPT-4-level intelligence at a fraction of the cost.
The Core Idea: Not Every Token Needs Every Parameter
Imagine you are at a university where students are learning different subjects. If every student were required to consult every professor on campus, the learning process would be chaotic and inefficient. Instead, each student should ideally consult only the professors who specialize in their subject.
Traditional transformers function like the first case, where every parameter is used regardless of relevance. MoE, on the other hand, acts like the second case — each token is routed only to the most relevant “professors” (experts).
In mathematical terms, if a model has E total experts but activates only K per token, then instead of computing over all parameters, the active computation per token is:
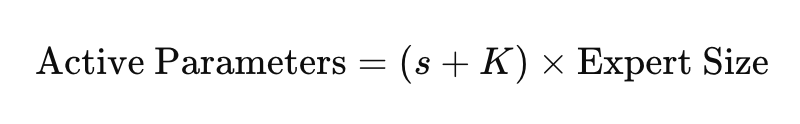
where s represents globally shared experts, and K denotes the top-K selected experts per token.
DeepSeek-V3’s architecture allows it to store knowledge across 671 billion parameters but only activates 37 billion at any given moment, making it functionally efficient while retaining vast knowledge storage capacity.
How DeepSeek-V3 Optimized Expert Selection
A critical challenge with MoE models is ensuring that experts are used effectively. If too many tokens route to the same few experts, some experts become overloaded while others remain idle. This is known as expert collapse, leading to inefficiency and underutilization of the model’s capacity.
Traditional MoE models, like Google’s Switch Transformer, tried to address this by adding an auxiliary load-balancing loss — a penalty applied when tokens distribute unevenly across experts. However, this often degraded model quality, as it forced tokens to spread out artificially rather than letting them naturally flow to the best experts.
DeepSeek-V3 eliminates the need for an auxiliary loss through adaptive bias correction. Instead of manually forcing expert balance, the model learns a bias term that dynamically adjusts after each training step.

If an expert receives too many tokens in one batch, its bias is reduced, making it less likely to be chosen in the next step. Conversely, if an expert is underutilized, its bias is increased, making it more attractive for selection.
By removing the explicit auxiliary loss penalty and letting the model self-regulate its load balancing, DeepSeek-V3 achieves stable expert utilization without compromising accuracy.
Shared vs. Routed Experts: Balancing Generalization and Specialization
A unique improvement in DeepSeek-V3 is the introduction of shared experts.
Most MoE models assign tokens only to specialized experts, meaning that different inputs activate entirely different sections of the model. DeepSeek-V3, however, blends specialization with generalization by introducing shared experts that every token passes through.
This is like a university system where every student must take a set of general education courses (shared experts) in addition to their specialized major courses (routed experts).
Why is this useful?
- Shared experts improve generalization: Common patterns in language (e.g., syntax, grammar) are better handled when certain experts are always activated.
- Caching and efficiency gains: Since shared experts are used for all inputs, their computations can be cached, reducing redundant calculations across tokens.
- Finer-grained expert selection: With a mix of shared and routed experts, tokens receive both broad and highly specific knowledge without overloading the system.
Mathematically, the total number of active parameters per token now includes both shared and routed experts:

where ss shared experts provide foundational knowledge, while KK routed experts provide specialized insight.
This strategy ensures every token benefits from baseline knowledge while still leveraging deep specialization.
Parallelism and Efficient Expert Routing
DeepSeek-V3 doesn’t just optimize expert selection — it also reduces communication overhead, which is a major bottleneck in large-scale MoE models.
When training on 2,048 GPUs, naive MoE routing would require tokens to communicate across thousands of nodes, causing huge network congestion. Instead, DeepSeek-V3 caps the number of nodes each token’s experts can be spread across.
Instead of routing a token’s computation across the entire 2,048-GPU cluster, DeepSeek-V3 restricts expert selection to at most 4 nodes per token.
This prevents combinatorial explosion in cross-node communication, keeping training bandwidth-efficient while retaining the benefits of MoE scaling.
Challenges of DeepSeek-V3’s MoE Approach
While DeepSeek-V3’s MoE implementation is a significant improvement over previous models, it is not without trade-offs.
- Inference complexity: During training, tokens are dynamically assigned to experts, but inference-time routing must be deterministic for fast generation. DeepSeek-V3 must store and quickly retrieve expert assignments to avoid excessive recomputation.
- Potential expert under-utilization: While bias correction balances expert load, there is still a possibility that some experts remain underutilized for certain input distributions.
- Tuning expert capacity: Setting the correct number of K routed experts per token is crucial — too few and the model loses its specialization benefits, too many and it loses efficiency.
Despite these challenges, DeepSeek-V3’s MoE refinements ensure high efficiency, balanced expert utilization, and minimal communication overhead, making it one of the most advanced sparse models ever built.
Conclusion: Smarter Scaling for the Future of AI
DeepSeek-V3 proves that bigger isn’t always better — smarter is better. Instead of activating hundreds of billions of parameters for every token, it activates only the most relevant subset, leading to massive efficiency gains.
With adaptive bias correction, a blend of shared and routed experts, and optimized parallel routing, DeepSeek-V3 makes MoE not just viable, but an essential tool for scaling AI models efficiently.
In the next blog, we will explore DeepSeek-V3’s memory optimizations, including FP8 quantization and low-rank attention mechanisms, which further reduce computational overhead while maintaining top-tier performance.
What are your thoughts on MoE’s role in AI’s future? Drop a comment and let’s discuss.
All Blog Links:
1. Blog-1: DeepSeek-V3 Blog 1: Redefining AI Efficiency — An Exclusive Series
2. Blog-2: DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
3. Blog-3: DeepSeek-V3 Blog 3: Smarter Memory Optimization — The Key to Training a 671B Model on Just 2048 GPUs
5. Blog-5: DeepSeek-V3 Blog 5: Low-Precision Training — The FP8 Revolution in Large-Scale AI
6. Blog-6: DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
7. Blog-7: DeepSeek-V3 Blog 7: Faster Inference with Shared Experts — The Key to Efficient AI Generation
8. Blog-8: DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together