- Published on
DeepSeek-V3 Blog 4: Faster, Smarter, and More Efficient — How Multi-Token Prediction and…
- Authors

- Name
- AIFlection
DeepSeek-V3 Blog 4: Faster, Smarter, and More Efficient — How Multi-Token Prediction and…
DeepSeek-V3 Blog 4: Faster, Smarter, and More Efficient — How Multi-Token Prediction and Multi-Head Latent Attention Redefine LLM Inference
Introduction: Breaking the Inference Bottleneck in Large Language Models
Large-scale language models like DeepSeek-V3 are not just about training efficiently — they must also generate responses quickly and accurately. Inference, the process of making predictions, is often constrained by memory bottlenecks, slow token generation, and expensive attention mechanisms. DeepSeek-V3 introduces two groundbreaking techniques to overcome these issues:
- Multi-Token Prediction (MTP): Instead of predicting just the next token, the model learns to anticipate future tokens, improving coherence and enabling faster inference.
- Multi-Head Latent Attention (MLA): A more memory-efficient attention mechanism that compresses key-value (KV) storage while maintaining accuracy.
These optimizations significantly improve speed, memory efficiency, and reasoning ability without requiring additional computational power. This blog will explain how these techniques work, breaking them down with mathematical interpretations and intuitive examples.
Multi-Token Prediction (MTP): Generating Multiple Tokens at Once
The Problem with Single-Token Generation
Most transformer-based language models generate text one token at a time. This means for a sentence like:
“The cat sat on the…”
The model predicts one word at a time, waiting for each token before computing the next. This is slow and inefficient because each prediction requires an entire forward pass through the network.
DeepSeek-V3 changes this by using Multi-Token Prediction (MTP), where it predicts multiple future tokens in parallel during training.
Mathematical Formulation of MTP

Intuition: The Chess Player Analogy
Imagine two chess players.
- Player A (Standard LLMs): Thinks one move ahead, making decisions only based on the immediate best move.
- Player B (DeepSeek-V3): Thinks two moves ahead, predicting how the opponent will respond and planning accordingly.
By looking ahead, Player B plays faster and makes smarter moves — just like how DeepSeek-V3 improves its fluency by anticipating multiple tokens at once.
How MTP Boosts Inference Speed: Speculative Decoding
One of the key benefits of MTP is that it allows for speculative decoding, where the model can guess the next token and verify it in parallel, effectively generating two tokens at once.
Consider a scenario where the model predicts the next token normally while simultaneously using the MTP head to predict an extra token:
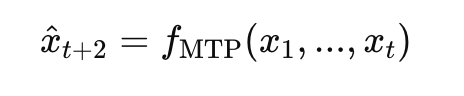
If the guessed token is correct, it is accepted immediately, skipping one full inference step. If it is incorrect, a fallback mechanism ensures correctness.
This method can reduce latency by nearly 50% in some cases, making DeepSeek-V3 one of the fastest LLMs for real-time applications.
Multi-Head Latent Attention (MLA): Efficient Memory Usage for Long Contexts
The Challenge of Attention Memory Growth
Self-attention mechanisms require storing key-value (KV) pairs for all past tokens. This KV cache grows linearly with context length, consuming enormous memory for long sequences.
For a context length of 4096 tokens, the memory required to store key-value pairs per head is:

where LL is the number of tokens and dd is the attention head size.
DeepSeek-V3 introduces Multi-Head Latent Attention (MLA) to reduce KV memory while preserving accuracy.
How MLA Works: Compression in the Attention Mechanism
Instead of storing full-size key-value vectors for every token, MLA projects them into a lower-dimensional latent space and stores only compressed representations.

Intuition: Storing Notes Instead of Full Conversations
Imagine trying to remember a long conversation.
- Standard Attention: You store every single word verbatim, requiring massive memory.
- MLA: You write down key takeaways and main points, compressing the conversation into a summary that still preserves its meaning.
MLA works the same way — by summarizing stored information, it reduces memory usage without losing much context.
Mathematical Savings: KV Cache Size Reduction

Trade-offs and Challenges in MLA and MTP
1. MTP Challenge: Incorrect Guesses in Speculative Decoding
While MTP speeds up generation, it relies on the assumption that future token predictions are mostly correct. If the second token is frequently wrong, the model must redo calculations, potentially negating the performance gains.
2. MLA Challenge: Balancing Compression and Accuracy
Reducing KV memory through MLA introduces a risk:
- Too much compression → Information loss, weakening long-term coherence.
- Too little compression → Memory savings are minimal.
DeepSeek-V3 carefully tunes dz to balance efficiency and accuracy, ensuring memory reduction without significant performance degradation.
Conclusion: Smarter Inference, Faster Responses
By combining Multi-Token Prediction (MTP) and Multi-Head Latent Attention (MLA), DeepSeek-V3 sets a new standard in efficient inference:
- MTP allows faster text generation by anticipating multiple tokens at once, reducing response latency.
- MLA reduces KV cache size, enabling longer context retention without excessive memory growth.
These innovations make DeepSeek-V3 not only a cost-effective model for training but also one of the fastest large language models for deployment.
In our next blog, we will dive into DeepSeek-V3’s advanced quantization strategies, including FP8 precision training, how it avoids numerical instability, and why this technique is a game-changer for cost-efficient AI training.
Would you be comfortable running an FP8-trained model in production? What challenges do you foresee with these optimizations? Let’s discuss.
All Blog Links:
1. Blog-1: DeepSeek-V3 Blog 1: Redefining AI Efficiency — An Exclusive Series
2. Blog-2: DeepSeek-V3 Blog 2: The Smartest Use of Mixture of Experts (MoE) in AI Yet
3. Blog-3: DeepSeek-V3 Blog 3: Smarter Memory Optimization — The Key to Training a 671B Model on Just 2048 GPUs
5. Blog-5: DeepSeek-V3 Blog 5: Low-Precision Training — The FP8 Revolution in Large-Scale AI
6. Blog-6: DeepSeek-V3 Blog 6: Hardware-Level Optimizations — Engineering AI for Peak Efficiency
7. Blog-7: DeepSeek-V3 Blog 7: Faster Inference with Shared Experts — The Key to Efficient AI Generation
8. Blog-8: DeepSeek-V3 Blog 8: The Final Piece — Bringing It All Together